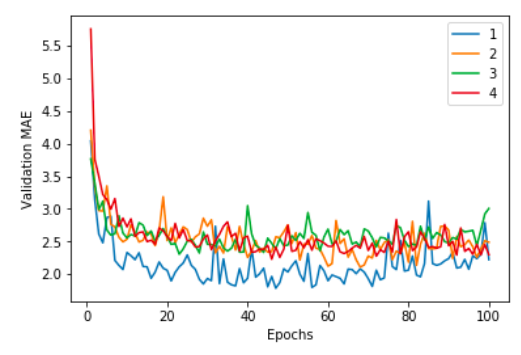
這個範例用來在樣本數相對少的案例,我們需要先把 訓練資料分成k群,把其中一群留下來當作是驗證,輪流shuffle k次. 例如,k=4,則把訓練資料分成四群,每次把其中一群保留不訓練,只做為validation的樣本,此種方式又稱為LOO(leave one out)
from keras.datasets import boston_housing
from keras import models
from keras import layers
#載入波士頓房價
(train_data,train_labels),(test_data,test_labels)=boston_housing.load_data()
#處理data
mean=train_data.mean(axis=0)
train_data-=mean
std=train_data.std(axis=0)
train_data/=std
test_data-=mean
test_data/=std
test_data.shape
#(102, 13) 共有102筆測試用data,每筆data有13個特徵值
train_data.shape
(404, 13)
#(404, 13) 共有404筆訓練用data,每筆data有13個特徵值
#建立模型
def build_model():
model=models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop',loss='mse',metrics=['mae']) #mse: mean square error; mae: mean absolute error
return model
#把訓練資料分成k群,用for迴圈shuffle k次
k=4
num_val_samples=len(train_data)//4
num_epochs=100
all_scores=[]
for i in range(k):
print('processing for #',i)
val_data=train_data[i*num_val_samples:(i+1)*num_val_samples]
val_targets=train_labels[i*num_val_samples:(i+1)*num_val_samples]
partial_train_data=np.concatenate([train_data[:i*num_val_samples],train_data[(i+1)*num_val_samples:]],axis=0)
partial_train_labels=np.concatenate([train_labels[:i*num_val_samples],train_labels[(i+1)*num_val_samples:]],axis=0)
model=build_model()
history=model.fit(partial_train_data,partial_train_labels, validation_data=(val_data,val_targets),epochs=num_epochs, batch_size=1,verbose=0)
# val_mse,val_mae=model.evaluate(val_data,val_targets,verbose=1)
mae_history=history.history['val_mean_absolute_error']
all_scores.append(mae_history)
#視覺化訓練過程
import matplotlib.pyplot as plt
for i in range(k):
plt.plot(range(1,len(all_scores[i])+1),all_scores[i])
plt.legend([1,2,3,4])
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()