Content-based image retrieval (CBIR)
參考資料:
步驟:
-
使用CNN autoencoder把圖片進行編碼,用中間的隱藏層(encoded layer)當作是濃縮的Features.用kaggles的人物照片去做un-supervised training,訓練機器找出圖片的特徵值.
-
把所有圖片拿進去編碼,找出特徵值.
-
將要尋找的圖片編碼,並用sklearn.neighbors.NearestNeighbors找出距離最接近的五張圖片.
 In [1]:
from keras.datasets import mnist
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model, load_model
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2
import os
from PIL import *
from pylab import *
%matplotlib inline
from sklearn.neighbors import NearestNeighbors
from keras.callbacks import ModelCheckpoint, EarlyStopping
In [1]:
from keras.datasets import mnist
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model, load_model
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2
import os
from PIL import *
from pylab import *
%matplotlib inline
from sklearn.neighbors import NearestNeighbors
from keras.callbacks import ModelCheckpoint, EarlyStopping
/Users/laihunglai/anaconda3/envs/py35/lib/python3.5/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
In [2]:
output_path = os.getcwd()
path = os.path.join(output_path, 'image')
data_list = os.listdir(path)
In [3]:
image_array=[]
color_array=[]
for i in data_list:
fig_path = os.path.join(path, i)
fig=cv2.imread(fig_path)
gray = cv2.cvtColor(fig, cv2.COLOR_BGR2GRAY)/255.
fig_small=cv2.resize(gray,(28,28),interpolation=cv2.INTER_CUBIC)
fig_small=fig_small.reshape(28,28,1)
color_array.append(fig)
image_array.append(fig_small)
# plt.plot()
# imshow(fig)
# plt.show()
# print(fig_path)
In [4]:
image_array=np.array(image_array)
size = len(image_array)
mask = np.random.rand(size)
train_mask=mask<0.8
test_mask=mask>0.8
In [5]:
X_train = image_array[train_mask]
X_test = image_array[test_mask]
In [7]:
input_img = Input(shape=(28,28,1))
x = Conv2D(16,(3,3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2,2), padding='same')(x)
x = Conv2D(8,(3,3), activation='relu', padding='same')(x)
x = MaxPooling2D((2,2), padding='same')(x)
x = Conv2D(8,(3,3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2,2), padding='same', name='encoder')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
#設定編碼器的輸入與輸出
encoder = Model(input_img, encoded)
#設定自動編碼器(編碼器+解碼器)的輸入與輸出
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
In [8]:
#編碼器摘要
autoencoder.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 8) 1160
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 8) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 8) 584
_________________________________________________________________
encoder (MaxPooling2D) (None, 4, 4, 8) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 4, 4, 8) 584
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 8, 8, 8) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 8) 584
_________________________________________________________________
up_sampling2d_2 (UpSampling2 (None, 16, 16, 8) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 14, 14, 16) 1168
_________________________________________________________________
up_sampling2d_3 (UpSampling2 (None, 28, 28, 16) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 4,385
Trainable params: 4,385
Non-trainable params: 0
_________________________________________________________________
In [9]:
# 訓練編碼器(輸入=輸出)
es = EarlyStopping(monitor='val_loss', mode='min', verbose=0, patience=5)
mc = ModelCheckpoint('face_searching.h5', monitor='val_loss', mode='min', verbose=2, save_best_only=True)
history=autoencoder.fit(X_train, X_train,epochs=50,batch_size=256,shuffle=True, validation_split=0.2, verbose=2, callbacks=[es, mc])
Train on 7272 samples, validate on 1819 samples
Epoch 1/50
- 83s - loss: 0.0791 - val_loss: 0.0729
Epoch 00001: val_loss improved from inf to 0.07290, saving model to face_searching.h5
Epoch 2/50
- 80s - loss: 0.0570 - val_loss: 0.0450
Epoch 00002: val_loss improved from 0.07290 to 0.04500, saving model to face_searching.h5
Epoch 3/50
- 76s - loss: 0.0397 - val_loss: 0.0350
Epoch 00003: val_loss improved from 0.04500 to 0.03501, saving model to face_searching.h5
Epoch 4/50
- 79s - loss: 0.0332 - val_loss: 0.0309
Epoch 00004: val_loss improved from 0.03501 to 0.03094, saving model to face_searching.h5
Epoch 5/50
- 83s - loss: 0.0302 - val_loss: 0.0287
Epoch 00005: val_loss improved from 0.03094 to 0.02874, saving model to face_searching.h5
Epoch 6/50
- 80s - loss: 0.0285 - val_loss: 0.0278
Epoch 00006: val_loss improved from 0.02874 to 0.02780, saving model to face_searching.h5
Epoch 7/50
- 81s - loss: 0.0275 - val_loss: 0.0264
Epoch 00007: val_loss improved from 0.02780 to 0.02641, saving model to face_searching.h5
Epoch 8/50
- 84s - loss: 0.0265 - val_loss: 0.0260
Epoch 00008: val_loss improved from 0.02641 to 0.02602, saving model to face_searching.h5
Epoch 9/50
- 81s - loss: 0.0257 - val_loss: 0.0250
Epoch 00009: val_loss improved from 0.02602 to 0.02499, saving model to face_searching.h5
Epoch 10/50
- 77s - loss: 0.0251 - val_loss: 0.0244
Epoch 00010: val_loss improved from 0.02499 to 0.02444, saving model to face_searching.h5
Epoch 11/50
- 75s - loss: 0.0246 - val_loss: 0.0239
Epoch 00011: val_loss improved from 0.02444 to 0.02394, saving model to face_searching.h5
Epoch 12/50
- 75s - loss: 0.0241 - val_loss: 0.0236
Epoch 00012: val_loss improved from 0.02394 to 0.02359, saving model to face_searching.h5
Epoch 13/50
- 75s - loss: 0.0237 - val_loss: 0.0231
Epoch 00013: val_loss improved from 0.02359 to 0.02314, saving model to face_searching.h5
Epoch 14/50
- 75s - loss: 0.0234 - val_loss: 0.0229
Epoch 00014: val_loss improved from 0.02314 to 0.02286, saving model to face_searching.h5
Epoch 15/50
- 75s - loss: 0.0230 - val_loss: 0.0226
Epoch 00015: val_loss improved from 0.02286 to 0.02256, saving model to face_searching.h5
Epoch 16/50
- 74s - loss: 0.0228 - val_loss: 0.0223
Epoch 00016: val_loss improved from 0.02256 to 0.02226, saving model to face_searching.h5
Epoch 17/50
- 77s - loss: 0.0226 - val_loss: 0.0221
Epoch 00017: val_loss improved from 0.02226 to 0.02205, saving model to face_searching.h5
Epoch 18/50
- 76s - loss: 0.0222 - val_loss: 0.0218
Epoch 00018: val_loss improved from 0.02205 to 0.02181, saving model to face_searching.h5
Epoch 19/50
- 75s - loss: 0.0220 - val_loss: 0.0221
Epoch 00019: val_loss did not improve from 0.02181
Epoch 20/50
- 75s - loss: 0.0221 - val_loss: 0.0214
Epoch 00020: val_loss improved from 0.02181 to 0.02143, saving model to face_searching.h5
Epoch 21/50
- 75s - loss: 0.0216 - val_loss: 0.0212
Epoch 00021: val_loss improved from 0.02143 to 0.02123, saving model to face_searching.h5
Epoch 22/50
- 76s - loss: 0.0215 - val_loss: 0.0211
Epoch 00022: val_loss improved from 0.02123 to 0.02109, saving model to face_searching.h5
Epoch 23/50
- 76s - loss: 0.0214 - val_loss: 0.0209
Epoch 00023: val_loss improved from 0.02109 to 0.02095, saving model to face_searching.h5
Epoch 24/50
- 77s - loss: 0.0211 - val_loss: 0.0208
Epoch 00024: val_loss improved from 0.02095 to 0.02079, saving model to face_searching.h5
Epoch 25/50
- 80s - loss: 0.0210 - val_loss: 0.0208
Epoch 00025: val_loss did not improve from 0.02079
Epoch 26/50
- 77s - loss: 0.0209 - val_loss: 0.0208
Epoch 00026: val_loss did not improve from 0.02079
Epoch 27/50
- 76s - loss: 0.0208 - val_loss: 0.0205
Epoch 00027: val_loss improved from 0.02079 to 0.02046, saving model to face_searching.h5
Epoch 28/50
- 76s - loss: 0.0207 - val_loss: 0.0204
Epoch 00028: val_loss improved from 0.02046 to 0.02043, saving model to face_searching.h5
Epoch 29/50
- 77s - loss: 0.0206 - val_loss: 0.0202
Epoch 00029: val_loss improved from 0.02043 to 0.02024, saving model to face_searching.h5
Epoch 30/50
- 76s - loss: 0.0206 - val_loss: 0.0202
Epoch 00030: val_loss improved from 0.02024 to 0.02018, saving model to face_searching.h5
Epoch 31/50
- 76s - loss: 0.0204 - val_loss: 0.0201
Epoch 00031: val_loss improved from 0.02018 to 0.02006, saving model to face_searching.h5
Epoch 32/50
- 76s - loss: 0.0203 - val_loss: 0.0202
Epoch 00032: val_loss did not improve from 0.02006
Epoch 33/50
- 76s - loss: 0.0203 - val_loss: 0.0199
Epoch 00033: val_loss improved from 0.02006 to 0.01993, saving model to face_searching.h5
Epoch 34/50
- 76s - loss: 0.0202 - val_loss: 0.0198
Epoch 00034: val_loss improved from 0.01993 to 0.01984, saving model to face_searching.h5
Epoch 35/50
- 76s - loss: 0.0201 - val_loss: 0.0199
Epoch 00035: val_loss did not improve from 0.01984
Epoch 36/50
- 76s - loss: 0.0200 - val_loss: 0.0197
Epoch 00036: val_loss improved from 0.01984 to 0.01971, saving model to face_searching.h5
Epoch 37/50
- 77s - loss: 0.0200 - val_loss: 0.0198
Epoch 00037: val_loss did not improve from 0.01971
Epoch 38/50
- 76s - loss: 0.0200 - val_loss: 0.0196
Epoch 00038: val_loss improved from 0.01971 to 0.01956, saving model to face_searching.h5
Epoch 39/50
- 79s - loss: 0.0198 - val_loss: 0.0195
Epoch 00039: val_loss improved from 0.01956 to 0.01952, saving model to face_searching.h5
Epoch 40/50
- 82s - loss: 0.0197 - val_loss: 0.0194
Epoch 00040: val_loss improved from 0.01952 to 0.01945, saving model to face_searching.h5
Epoch 41/50
- 77s - loss: 0.0197 - val_loss: 0.0194
Epoch 00041: val_loss improved from 0.01945 to 0.01942, saving model to face_searching.h5
Epoch 42/50
- 77s - loss: 0.0196 - val_loss: 0.0194
Epoch 00042: val_loss improved from 0.01942 to 0.01940, saving model to face_searching.h5
Epoch 43/50
- 77s - loss: 0.0196 - val_loss: 0.0193
Epoch 00043: val_loss improved from 0.01940 to 0.01934, saving model to face_searching.h5
Epoch 44/50
- 75s - loss: 0.0196 - val_loss: 0.0194
Epoch 00044: val_loss did not improve from 0.01934
Epoch 45/50
- 77s - loss: 0.0195 - val_loss: 0.0192
Epoch 00045: val_loss improved from 0.01934 to 0.01919, saving model to face_searching.h5
Epoch 46/50
- 76s - loss: 0.0193 - val_loss: 0.0192
Epoch 00046: val_loss improved from 0.01919 to 0.01919, saving model to face_searching.h5
Epoch 47/50
- 76s - loss: 0.0194 - val_loss: 0.0191
Epoch 00047: val_loss improved from 0.01919 to 0.01905, saving model to face_searching.h5
Epoch 48/50
- 76s - loss: 0.0193 - val_loss: 0.0191
Epoch 00048: val_loss did not improve from 0.01905
Epoch 49/50
- 76s - loss: 0.0193 - val_loss: 0.0189
Epoch 00049: val_loss improved from 0.01905 to 0.01893, saving model to face_searching.h5
Epoch 50/50
- 75s - loss: 0.0192 - val_loss: 0.0189
Epoch 00050: val_loss improved from 0.01893 to 0.01890, saving model to face_searching.h5
In [10]:
autoencoder.save('face_searching_autoencoder.h5')
encoder.save('face_searching_encoder.h5')
In [12]:
model = load_model('face_searching.h5')
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 8) 1160
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 8) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 8) 584
_________________________________________________________________
encoder (MaxPooling2D) (None, 4, 4, 8) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 4, 4, 8) 584
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 8, 8, 8) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 8) 584
_________________________________________________________________
up_sampling2d_2 (UpSampling2 (None, 16, 16, 8) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 14, 14, 16) 1168
_________________________________________________________________
up_sampling2d_3 (UpSampling2 (None, 28, 28, 16) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 4,385
Trainable params: 4,385
Non-trainable params: 0
_________________________________________________________________
In [15]:
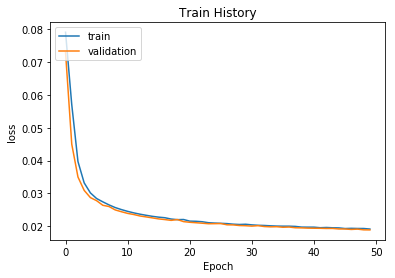
#視覺化訓練過程
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
#show_train_history(history,'mse','val_mse')
#若訓練(train)的準確度一直增加而驗證(validation)的準確度沒有一直增加則可能是overfit
#畫出loss誤差執行結果
show_train_history(history,'loss','val_loss')
 In [16]:
# 編碼資料
encoded_imgs = encoder.predict(X_test)
In [16]:
# 編碼資料
encoded_imgs = encoder.predict(X_test)
In [17]:
# 編碼+解碼資料
predicted = autoencoder.predict(X_test)
In [18]:
# 視覺化 編碼前資料,編碼後資料,解碼後資料
plt.figure(figsize=(40, 4))
for i in range(10):
# display original images
ax = plt.subplot(3, 20, i + 1)
plt.imshow(X_train[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display encoded images
ax = plt.subplot(3, 20, i + 1 + 20)
plt.imshow(encoded_imgs[i].reshape(16,8))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstructed images
ax = plt.subplot(3, 20, 2*20 +i+ 1)
plt.imshow(predicted[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
 In [37]:
# 編碼資料
encoded_imgs = encoder.predict(image_array)
encoded_imgs=encoded_imgs.reshape(11389,4*4*8)
# Fit the NN algorithm to the encoded test set
nbrs = NearestNeighbors(n_neighbors=5).fit(encoded_imgs)
In [37]:
# 編碼資料
encoded_imgs = encoder.predict(image_array)
encoded_imgs=encoded_imgs.reshape(11389,4*4*8)
# Fit the NN algorithm to the encoded test set
nbrs = NearestNeighbors(n_neighbors=5).fit(encoded_imgs)
# Find the closest images to the encoded query image
distances, indices = nbrs.kneighbors(np.array(encoded_imgs[1].reshape(1, -1)))
In [38]:
# 視覺化 編碼前資料,編碼後資料,解碼後資料
plt.figure(figsize=(200, 200))
ax = plt.subplot(5, 10, 1)
plt.imshow(image_array[1].reshape(28, 28))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
for i in range(len(indices[0])):
# display original images
# display encoded images
ax = plt.subplot(5, 10, i + 2)
plt.imshow(image_array[indices[0][i]].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
 In [39]:
#輸入要查詢的照片
fig=cv2.imread('test image/yu.png')
gray = cv2.cvtColor(fig, cv2.COLOR_BGR2GRAY)/255.
fig_small=cv2.resize(gray,(28,28),interpolation=cv2.INTER_CUBIC)
fig_small=fig_small.reshape(1,28,28,1)
# 將照片編碼
search_encoded_imgs = encoder.predict(fig_small)
In [39]:
#輸入要查詢的照片
fig=cv2.imread('test image/yu.png')
gray = cv2.cvtColor(fig, cv2.COLOR_BGR2GRAY)/255.
fig_small=cv2.resize(gray,(28,28),interpolation=cv2.INTER_CUBIC)
fig_small=fig_small.reshape(1,28,28,1)
# 將照片編碼
search_encoded_imgs = encoder.predict(fig_small)
# 找尋最接近的5張照片的距離和指標
distances, indices = nbrs.kneighbors(np.array(search_encoded_imgs[0].reshape(1, -1)))
# 視覺化 編碼前資料,編碼後資料,解碼後資料
plt.figure(figsize=(200, 200))
ax = plt.subplot(5, 10, 1)
plt.imshow(fig)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
for i in range(len(indices[0])):
# display original images
# display encoded images
ax = plt.subplot(5, 10, i + 2)
plt.imshow(color_array[indices[0][i]])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
 In [40]:
#輸入要查詢的照片
fig=cv2.imread('test image/cj.png')
gray = cv2.cvtColor(fig, cv2.COLOR_BGR2GRAY)/255.
fig_small=cv2.resize(gray,(28,28),interpolation=cv2.INTER_CUBIC)
fig_small=fig_small.reshape(1,28,28,1)
# 將照片編碼
search_encoded_imgs = encoder.predict(fig_small)
In [40]:
#輸入要查詢的照片
fig=cv2.imread('test image/cj.png')
gray = cv2.cvtColor(fig, cv2.COLOR_BGR2GRAY)/255.
fig_small=cv2.resize(gray,(28,28),interpolation=cv2.INTER_CUBIC)
fig_small=fig_small.reshape(1,28,28,1)
# 將照片編碼
search_encoded_imgs = encoder.predict(fig_small)
# 找尋最接近的5張照片的距離和指標
distances, indices = nbrs.kneighbors(np.array(search_encoded_imgs[0].reshape(1, -1)))
# 視覺化 編碼前資料,編碼後資料,解碼後資料
plt.figure(figsize=(200, 200))
ax = plt.subplot(5, 10, 1)
plt.imshow(fig)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
for i in range(len(indices[0])):
# display original images
# display encoded images
ax = plt.subplot(5, 10, i + 2)
plt.imshow(color_array[indices[0][i]])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)

使用CNN autoencoder把圖片進行編碼,用中間的隱藏層(encoded layer)當作是濃縮的Features.用kaggles的人物照片去做un-supervised training,訓練機器找出圖片的特徵值.
把所有圖片拿進去編碼,找出特徵值.
將要尋找的圖片編碼,並用sklearn.neighbors.NearestNeighbors找出距離最接近的五張圖片.


