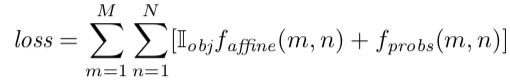自動車牌辨識系統 Automatic License Plate Recognition (ALPR)
論文來源:http://openaccess.thecvf.com/content_ECCV_2018/papers/Sergio_Silva_License_Plate_Detection_ECCV_2018_paper.pdf S´ergio Montazzolli等人於2018年發表用於扭曲車牌影像的辨識方法,結合卷積Convolutional Neural Network (CNN)與光學字元辨識Optical Character Recognition (OCR),其演算法得流程如下:
- 車輛偵測(演算法:YOLOv2)
- 車牌偵測(演算法:WPOD-NET):包含車牌偵測與車牌校正 (Rectification)(利用 Affine transformation 轉換影像)
- 光學字元辨識(演算法:OCR)

車輛偵測
車輛偵測的DL已經相對成熟,例如PASCAL-VOC, ImageNet, COCO等訓練資料和模型已經對車輛辨識有相當好的辨識成果,本篇論文使用YOLOv2 network是因為有較高的執行效率與精確度,並不改變訓練模型,直接將與車子有關的影像(汽車,公車,卡車)輸出至WPOD-NET.
車牌偵測
使用翹曲平面物體檢測神經網路Warped Planar Object Detection Network (WPOD-NET)演算法來辨識車牌影像.WPOD-NET可以學習找到扭曲的車牌與他的Affine transformation的regresses coefficients,並把它轉直視影像(frontal view)
回顧以前的圖像辨識演算法, YOLO, SSD and Spatial Transformer Networks (STN). YOLO, SSD可以快速的辨識影像中多個物體但並沒有考慮到空間扭曲,而STN有考慮套空間扭曲,但並不能同時對圖像中的多個物體進行辨識
WPOD-NET將YOLOv2輸出的向量作為輸入,並產生8個channels的特徵值對應編碼的affine transformation參數與影像是車牌的機率,現在把小框框的中點設為(m,n),若(m,n)的影像位置是車牌的機率高於threshold,則對這個小框框做affine matrix的向量變換,就可以變成直視的車牌影像.
這篇論文總共用了21層CNN,其中14層是在Residual blocks內,最後輸入兩個平行的CNN,其中一個CNN用來計算機率(用softmax),另一個CNN用來計算affine parameters(不用activation或F(x) = x)

損失函數
影像經過4次的MaxPooling後長度(m)和寬度(n)變成原來的長度(H)和寬度(W)的(1/2)^4.而最後輸出的深度則為8層.這八層深度資料的v1和v2是用來計算物體/非物體的機率,v3到v8則是用來計算affine transformation參數以用來建立affine transformation矩陣Tmn.
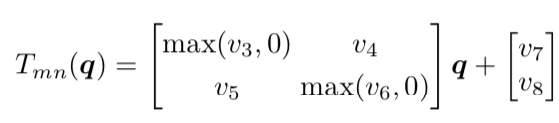
pi =[xi, yi]T, for i = 1,··· ,4為車牌的四角對應的座標
q1 = [−0.5, −0.5]T , q2 = [0.5, −0.5]T , q3 = [0.5, 0.5]T , q4 = [−0.5, 0.5]T 為正方形的四四角座標
因為影像經過4次的MaxPooling後長度(m)和寬度(n)變成原來的長度(H)和寬度(W)的(1/2)^4.需要將pi做re-scale和re-center

把pi和qi相減可以得到扭曲量的loss function
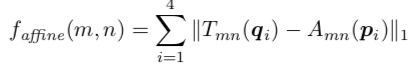
而判斷(m,n)是否有物體資訊的loss function如下
其中logloss(y, p) = −y log(p)
Iobj是object indicator,若點(m,n)有物體則Iobj=1,反之則為零
把以上兩個損失函數相加得到總損失