原文: https://github.com/osbarge/salesforecaster
https://towardsdatascience.com/time-series-forecasting-a-getting-started-guide-c435f9fa2216
原文使用SARIMAX (Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors)的統計學方法來預測產品銷售量.其預測結果如下:

https://towardsdatascience.com/time-series-forecasting-a-getting-started-guide-c435f9fa2216
原文使用SARIMAX (Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors)的統計學方法來預測產品銷售量.其預測結果如下:
在這個案例, 我們希望建立一個深度學習的模型利用過去一段時間的(天氣, 銷售量, 放假日)資料來預測未來的產品銷售量.
訓練資料:
- 過去銷售資料表 cant_ventas_2014-2019.csv
- 節日的資料表 feriados.csv
- 過去天氣的資料表 historical_weather_data.csv
import pandas as pd
from datetime import datetime
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from keras.layers import Dense
from keras.layers.recurrent import LSTM
from keras.models import Sequential
from keras import layers
from keras.layers.core import Activation, Dropout, Flatten
import time
from keras.callbacks import ModelCheckpoint, EarlyStopping
銷售資料表
path_to_ventas = r'data/cant_ventas_2014-2019.csv'
ventas_df = pd.read_csv(path_to_ventas)
ventas_df['fecha']=ventas_df.apply(lambda row:datetime.strptime(row['fecha'], '%d %B %Y'),axis=1)
ventas_df=ventas_df.set_index('fecha')
#檢查資料是否缺少數據
ventas_df.isnull().sum()
#將缺資料的補零
ventas_df['cantidad']=ventas_df['cantidad'].fillna(0)
#重新取樣
ventas_df = ventas_df.resample('D').mean()
#將資料做normalization
scaler = MinMaxScaler(feature_range=(0, 1))
data_df_scale = scaler.fit_transform(ventas_df.iloc[:,0].reshape(-1,1))
ventas_df['cantidad']=data_df_scale[:,0]
匯入節日資料表
path_to_feriados = r"data/feriados.csv"
feriados_df = pd.read_csv(path_to_feriados, delimiter=';', parse_dates=True, dayfirst=True)
天氣資料表
df_weather=pd.read_csv('data/historical_weather_data.csv')
df_weather['date'] = pd.to_datetime(df_weather['date'], format='%Y-%m-%d')
# convert column to datetime to make it index
df_weather['date'] = df_weather['date'].astype('datetime64[ns]')
df_weather.set_index('date', inplace=True)
columns=['temperature','windSpeed','precipIntensity']
df_weather=df_weather[columns]
df_weather.isnull().sum()
#向前補資料
df_weather=df_weather.fillna(method='ffill')
df_weather.isnull().sum()
#將資料做normalization
scaler_weather = MinMaxScaler(feature_range=(0, 1))
df_weather_scaled = scaler_weather.fit_transform(df_weather.iloc[:,:])
df_weather_scaled.shape
#重製表格
df_weather_scaled=pd.DataFrame(df_weather_scaled,index=df_weather.index,columns=df_weather.columns)
Join 三個資料表
data_df = ventas_df.join(feriados_df, how='left').join(df_weather_scaled, how='left')
data_df['cantidad'] = data_df['cantidad'].fillna(0)
# 檢查是否有奇怪的數值
data_df[data_df['cantidad'].isin([np.nan, np.inf, -np.inf])]
# 增加特徵值欄位
data_df['isweekday'] = [1 if d >= 0 and d <= 4 else 0 for d in data_df.index.dayofweek]
data_df['isweekend'] = [0 if d >= 0 and d <= 4 else 1 for d in data_df.index.dayofweek]
data_df['inbetween25and5'] = [1 if d >= 25 or d <= 5 else 0 for d in data_df.index.day]
data_df['holiday_weekend'] = [1 if (we == 1 and h not in [np.nan]) else 0 for we,h in data_df[['isweekend','Holiday']].values]
data_df['holiday_weekday'] = [1 if (wd == 1 and h not in [np.nan]) else 0 for wd,h in data_df[['isweekday','Holiday']].values]
# Drop irrelevant columns:
data_df.drop(columns=['Year', 'Month', 'Day', 'Weekday', 'Holiday', 'linea'], inplace=True, errors='ignore')
準備訓練資料
#訓練資料: 前80%; 測試資料: 後20%
train_size = int(len(data_df) * 0.80)
test_size = len(data_df) - train_size
train,test = data_df.iloc[0:train_size,:],data_df.iloc[train_size:len(data_df),:]
#train_X=train.iloc[1:,:]
#test_X=test.iloc[1:,:]
#train_Y=train.iloc[0,:]
#test_Y=test.iloc[0,:]
#轉換成Feature_X 和 Label_Y
def create_dataset(dataset, look_back=10):
dataX, dataY = [], []
for i in np.arange(len(dataset)-look_back-1):
a = dataset.iloc[i:(i+look_back), 2:].values
dataX.append(a)
b=dataset.iloc[(i+look_back), 0]
dataY.append(b)
return dataX, dataY
#轉換
look_back=30
trainX, trainY=create_dataset(train, look_back)
testX, testY=create_dataset(test, look_back)
trainX=np.array(trainX)
trainY=np.array(trainY)
testX=np.array(testX)
testY=np.array(testY)
print('trainX shape:',trainX.shape)
print('trainY shape:',trainY.shape)
print('testX shape:',testX.shape)
print('testY shape:',testY.shape)
#建立多層LSTM,最後用密集層輸出一維度的預測值
model = Sequential()
model.add(layers.Conv1D(32,5,activation='relu',padding='same',input_shape=(None,trainX[0].shape[-1])))
model.add(layers.MaxPool1D(3))
model.add(layers.Conv1D(32,5,activation='relu',padding='same'))
model.add(layers.MaxPool1D(3))
model.add(LSTM(32,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(32,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(32,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(32,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(32,return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(output_dim=1))
model.add(Activation('linear'))
start = time.time()
model.compile(loss='mse', optimizer='rmsprop', metrics=['mae'])
print ('compilation time : ', time.time() - start)
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_5 (Conv1D) (None, None, 32) 1312
_________________________________________________________________
max_pooling1d_5 (MaxPooling1 (None, None, 32) 0
_________________________________________________________________
conv1d_6 (Conv1D) (None, None, 32) 5152
_________________________________________________________________
max_pooling1d_6 (MaxPooling1 (None, None, 32) 0
_________________________________________________________________
lstm_11 (LSTM) (None, None, 32) 8320
_________________________________________________________________
dropout_11 (Dropout) (None, None, 32) 0
_________________________________________________________________
lstm_12 (LSTM) (None, None, 32) 8320
_________________________________________________________________
dropout_12 (Dropout) (None, None, 32) 0
_________________________________________________________________
lstm_13 (LSTM) (None, None, 32) 8320
_________________________________________________________________
dropout_13 (Dropout) (None, None, 32) 0
_________________________________________________________________
lstm_14 (LSTM) (None, None, 32) 8320
_________________________________________________________________
dropout_14 (Dropout) (None, None, 32) 0
_________________________________________________________________
lstm_15 (LSTM) (None, 32) 8320
_________________________________________________________________
dropout_15 (Dropout) (None, 32) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 33
_________________________________________________________________
activation_3 (Activation) (None, 1) 0
=================================================================
Total params: 48,097
Trainable params: 48,097
Non-trainable params: 0
_________________________________________________________________
es = EarlyStopping(monitor='val_loss', mode='min', verbose=0, patience=10)
mc = ModelCheckpoint('data/best_model.h5', monitor='val_loss', mode='min', verbose=2, save_best_only=True)
train_history=model.fit(trainX,trainY,batch_size=128,nb_epoch=100,validation_split=0.2,callbacks=[es, mc], verbose=0)
Epoch 00001: val_loss improved from inf to 0.02204, saving model to data/best_model.h5
Epoch 00002: val_loss improved from 0.02204 to 0.02159, saving model to data/best_model.h5
Epoch 00003: val_loss did not improve from 0.02159
Epoch 00004: val_loss improved from 0.02159 to 0.02052, saving model to data/best_model.h5
Epoch 00005: val_loss improved from 0.02052 to 0.01774, saving model to data/best_model.h5
Epoch 00006: val_loss improved from 0.01774 to 0.01596, saving model to data/best_model.h5
Epoch 00007: val_loss improved from 0.01596 to 0.01461, saving model to data/best_model.h5
Epoch 00008: val_loss did not improve from 0.01461
Epoch 00009: val_loss improved from 0.01461 to 0.01384, saving model to data/best_model.h5
Epoch 00010: val_loss improved from 0.01384 to 0.01379, saving model to data/best_model.h5
Epoch 00011: val_loss improved from 0.01379 to 0.01309, saving model to data/best_model.h5
Epoch 00012: val_loss did not improve from 0.01309
Epoch 00013: val_loss did not improve from 0.01309
Epoch 00014: val_loss did not improve from 0.01309
Epoch 00015: val_loss did not improve from 0.01309
Epoch 00016: val_loss improved from 0.01309 to 0.01175, saving model to data/best_model.h5
Epoch 00017: val_loss improved from 0.01175 to 0.01141, saving model to data/best_model.h5
Epoch 00018: val_loss did not improve from 0.01141
Epoch 00019: val_loss did not improve from 0.01141
Epoch 00020: val_loss did not improve from 0.01141
Epoch 00021: val_loss did not improve from 0.01141
Epoch 00022: val_loss did not improve from 0.01141
Epoch 00023: val_loss did not improve from 0.01141
Epoch 00024: val_loss did not improve from 0.01141
Epoch 00025: val_loss did not improve from 0.01141
Epoch 00026: val_loss did not improve from 0.01141
Epoch 00027: val_loss did not improve from 0.01141
import matplotlib.pyplot as plt
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train history')
plt.ylabel(train)
plt.yscale('log')
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history,'loss','val_loss')
show_train_history(train_history,'mean_absolute_error','val_mean_absolute_error')


predic=[]
for i in range(len(testX)):
a=model.predict(testX[i][np.newaxis,:])[0,0]
predic.append(a)
predictions_origins=scaler.inverse_transform(np.array(predic).reshape(-1, 1))
answer=scaler.inverse_transform(testY.reshape(-1,1))
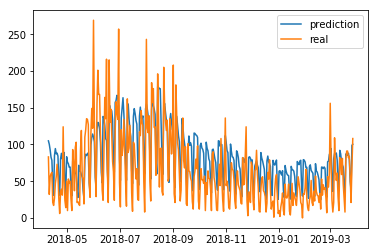
#畫出所有的測試範圍
test_date=ventas_df.index[-len(testX):]
plt.plot(test_date[:],predictions_origins[:],label='prediction');plt.plot(test_date[:],answer[:],label='real')
plt.legend()
plt.show()
#畫出30天預測結果
plt.plot(test_date[:30],predictions_origins[:30],label='prediction');plt.plot(test_date[:30],answer[:30],label='real')
plt.legend()
plt.show()



